When OpenAI has released ChatGPT it instantly took the internet by the storm. With one million users in just one week and 100 million actives in two months it became fastest growing app in history, overtaking even giants like TikTok, Instagram or Facebook.
Beside sheer popularity, ChatGPT sparked a deeper discussion about the future of Artificial Intelligence in our lives. With its applications in business, education or medicine, will the need for human specialists be superseded? While many people are talking about world-changing revolution let's take a deeper look at ChatGPT – what it really is, and what it is capable of.
ChatGPT acquired a lot of fame in such a rapid manner, that for a lot of people outside the AI community it seemed like a breakthrough we have never seen before. So lets ask the fundamental question – did the AI revolution really begin in the late 2022?
Transformer-based models, current kings of computational linguistics, are well known since 2017. They power modern Machine Learning solutions allowing us to classify documents, extract information and even generate texts. Generative Pre-Training (GPT [6]), published in 2018, was one of the first generative mod- els based on the Transformer architecture. Such a model is capable of generating new text in various tasks such as translation, summarization, or question answering.

In GPT-2 (2019), an extension of this concept, authors mainly focused on increasing the sheer size of the model. The input context length was doubled (from 512 to 1024) and the data for training increased to 40GB, but the total number of models trainable parameters soared from 117M (GPT) to 1.5B (GPT- 2). Two factors mainly distinguished the succeeding GPT-3 (2020) model: the number of model parameters increased to 175B and 45TB text data was used for training. OpenAIs strategy, bigger is better, kept bringing results, as the GPT-3 achieved outstanding outstanding results, especially in zero-shot and few-shot scenarios (i.e. scenarios where model has to answer questions about topics he never heard before). This is how we came to ChatGPT – the core of it was based on GTP-3 (2020) but was specifically adjusted for interacting with people (authors were relying on human feedback for training).
As we know, OpenAI’s child achieved tremendous success – it helped popularize Artificial Intelligence and bring our attention to new, innovative solutions in many areas of our lives. Still, as big of a commercial and public accomplishment ChatGPT has, from the technological point of view, it isn’t anything new. It certainly is a major improvement over previous generations of models, but it’s just another step in a long road ahead. Especially considering, that the core model inside of ChatGPT was known years before the public boom of 2022 it cannot be called ”revolutionary technology, like we have never seen before”.
To pinpoint Chat’sGPT strong and weak sides it is worth to take a look at an independent evaluation study. Researchers from CLARIN team have recently published a very comprehensive paper [4] testing the Chat on multiple benchmark datasets and comparing the results to known state-of-the-art models. Research team presented the models with various tasks from two main groups: semantic – recognition of text properties (i.e. sense description, a speaker’s stance etc.) or mining information that is directly expressed in a text fragment (i.e. relations between sentences) and pragmatic – ability to use general knowledge stored in the model to solve the tasks beyond the literal semantic content of the text.

The benchmark suite contained datasets widely used in the scientific AI community, among others:
The performance of Machine Learning models (in tasks such as this) is usually measured with F1macro score – it’s a universal metric of performance, that takes into account other factors, such as the imbalance of the dataset. Yet, for the clarity of the comparison, let’s look at the results in terms of Gain (how much ChatGPT is better than the best-dedicated methods) and Loss (how much the Chat is worse than the SOTA models) .
Figure 1: The Chat’sGPT percentage loss in performance. The upper X axis corresponds to the performance of the best model (SOTA), treated as 100%. Based on the work of Kocon et al. [4]
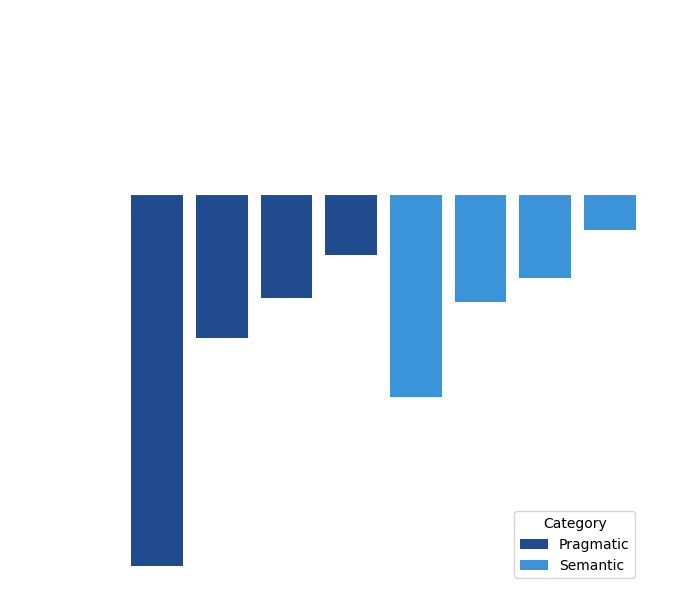
The crucial finding from the CLARIN’s team study is that the ChatGPT performance is always lower than the SOTA methods (loss > 0). While it is certainly remarkable, that the Chat managed to set a decent score in every task, it never reached the performance level of the best existing models. The average quality of SOTA methods was at 73.7%, whereas ChatGPT was at only 56.5%. Simultaneously, ChatGPT was less stable: the standard deviation of its performance was 23.3% compared to only 16.7% for the SOTA solutions.
ChatGPT is a remarkable achievement. While the studies show that it can be consistently outperformed by dedicated SOTA models, we cannot underestimate it is versatility. It has an amazing ability to deliver reasonable out-of-the-box solutions to a lot of language-based problems.
This allows us to draw certain conclusions about where ChatGPT fits in our world. With its convenient ”conversational” user interface it could become a part of our lives in a form of virtual assistant or educational aid. It also has a wide range of applications in the AI-boosting domain – helping the engineers develop better ML models. It can be used as an advanced textual augmentation mechanism or initial data annotator – providing silver standard for another models pretraining. General knowledge and cognitive abilities of the Chat also allow to quickly create a baseline, zero-shot model for knowledge-extraction tasks (i.e., NER). Such a prototype can be useful in many cases, but still – dedicated models will have the upper hand in performance, speed and efficiency. In commercial applications like intelligent automation or document processing, it is difficult to overlook these qualities.