Kiedy OpenAI udostępniło ChatGPT, natychmiast podbił on Internet. Z milionem użytkowników w ciągu zaledwie jednego tygodnia i 100 milionami aktywnych użytkowników w ciągu dwóch miesięcy stał się on najszybciej rozwijającą się aplikacją w historii, wyprzedzając nawet gigantów takich jak TikTok, Instagram czy Facebook.
Oprócz samej popularności, ChatGPT wywołał głębszą dyskusję na temat przyszłości sztucznej inteligencji w naszym życiu. Czy wraz z jego zastosowaniami w biznesie, edukacji lub medycynie zapotrzebowanie na specjalistów w danych dziedzinach spadnie? Podczas gdy wiele osób mówi o rewolucji zmieniającej świat, my przyjrzymy się głębiej ChatGPT - czym naprawdę jest i do czego jest zdolny.
ChatGPT zyskał dużą sławę w tak szybki sposób, że dla wielu osób spoza społeczności AI wydawało się to przełomem, którego nigdy wcześniej nie widzieliśmy. Zadajmy więc fundamentalne pytanie – czy rewolucja AI naprawdę rozpoczęła się pod koniec 2022 roku?
Modele oparte na transformerach, obecni królowie lingwistyki komputerowej, są dobrze znane od 2017 roku. Napędzają nowoczesne rozwiązania Machine Learning, pozwalając nam klasyfikować dokumenty, wydobywać informacje, a nawet generować teksty. Generative Pre-Training (GPT [6]), opublikowany w 2018 roku, był jednym z pierwszych generatywnych modeli opartych na architekturze Transformer. Taki model jest w stanie wygenerować nowy tekst w różnych zadaniach, takich jak tłumaczenie, streszczanie lub odpowiadanie na pytania.

W GPT-2 (2019), rozszerzeniu pierwotnej koncepcji, autorzy skupili się głównie na zwiększeniu samego rozmiaru modelu. Długość tekstu wejściowego została podwojona (z 512 do 1024 tokenów), a ilość danych do treningu wzrosła do 40 GB, ponadto całkowita liczba parametrów trenowania modeli zwiększyła się ze 117 mln (GPT) do 1,5 mld (GPT-2). Kolejny model GPT-3 (2020) wyróżniały głównie dwa czynniki: liczba parametrów modelu wzrosła do 175B, a do treningu wykorzystano dane tekstowe o objętości 45TB. Strategia OpenAI – więcej znaczy lepiej – przynosiła rezultaty, ponieważ GPT-3 osiągał znakomite wyniki, szczególnie w scenariuszach zero-shot i few shot (tj. Scenariuszach, w których model musi odpowiadać na pytania dotyczące tematów, o których nigdy wcześniej nie słyszał). W ten sposób doszliśmy do ChatGPT – jego rdzeń został oparty na GTP-3 (2020), lecz został specjalnie dostosowany do interakcji z ludźmi (autorzy polegali na ludzkich opiniach podczas szkolenia).
Jak wiemy, dziecko OpenAI odniosło ogromny sukces – pomogło spopularyzować Sztuczną Inteligencję i zwrócić naszą uwagę na nowe, innowacyjne rozwiązania w wielu dziedzinach naszego życia. Mimo, że ChatGPT to komercyjne i publiczne duże osiągnięcie, z technologicznego punktu widzenia nie jest to nic nowego. Z pewnością jest znacząco lepszy od poprzednich generacji modeli, ale to tylko kolejny krok na długiej drodze. Zwłaszcza, że podstawowy model wewnątrz ChatGPT był znany na wiele lat przed publicznym boomem w 2022 roku, zatem nie można go nazwać „rewolucyjną technologią, jakiej nigdy wcześniej nie widzieliśmy”.
Aby wskazać mocne i słabe strony ChatGPT, warto przyjrzeć się niezależnemu badaniu ewaluacyjnemu. Naukowcy z zespołu CLARIN opublikowali niedawno bardzo obszerny artykuł [4] testujący czat na wielu zestawach danych porównawczych i zestawili wyniki z najnowocześniejszymi znanymi modelami (state-of-the-art - SOTA). Zespół badawczy przetestował modele na różnych zadaniach z dwóch głównych grup: semantycznej – rozpoznawanie właściwości tekstu (tj. opisu sensu, postawy mówcy itp.) lub wydobywanie informacje, które są bezpośrednio wyrażone we wskazanym fragmencie (tj. relacje między zdaniami) oraz pragmatycznej – umiejętności wykorzystania wiedzy ogólnej zapisanej w modelu do rozwiązywania zadań wykraczających poza dosłowną treść semantyczną tekstu.

Zestaw porównawczy zawierał zbiory danych szeroko stosowane w społeczności naukowej AI, między innymi:
Wydajność modeli Machine Learning (w zadaniach takich jak to) jest zwykle mierzona wynikiem F1macro – jest to uniwersalna miara wydajności, która poza dokładnością modelu uwzględnia także inne czynniki, takie jak brak równowagi klas w zbiorze danych. Jednak dla jasności porównania spójrzmy na wyniki pod względem korzyści (o ile ChatGPT jest lepszy niż najlepsze dedykowane metody) i strat (o ile Chat jest gorszy od modeli SOTA).
Rysunek 1: Procentowa utrata wydajności GPT czatu. Górna oś X odpowiada osiągom najlepszego modelu (SOTA), traktowanym jako 100%. Na podstawie pracy Kocon i in. [4]
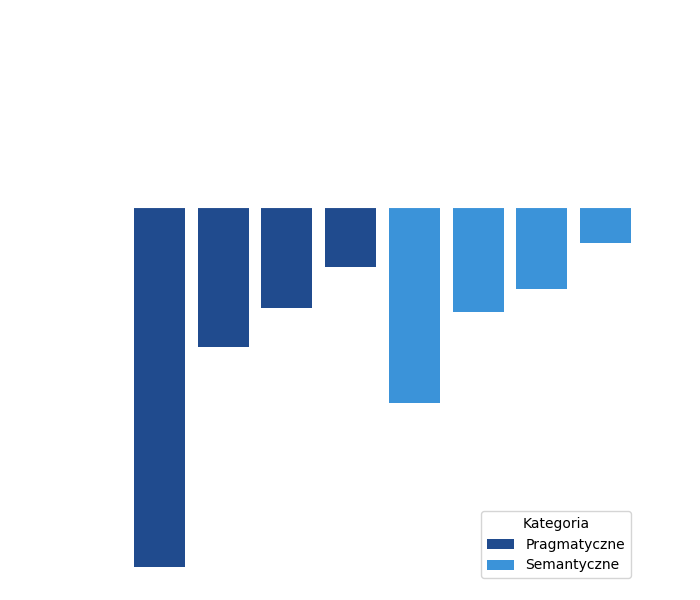
Kluczowym wnioskiem z badania zespołu CLARIN jest to, że wydajność ChatGPT jest zawsze niższa niż metody SOTA (strata > 0). Chociaż z pewnością niezwykłe jest to, że czat zdołał ustanowić przyzwoity wynik w każdym zadaniu, nigdy nie osiągnął poziomu wydajności najlepszych istniejących modeli. Średnia jakość modeli SOTA wyniosła 73,7%, podczas gdy ChatGPT osiągnął tylko 56,5%. Jednocześnie ChatGPT był mniej stabilny: odchylenie standardowe jego wydajności wyniosło 23,3% w porównaniu do zaledwie 16,7% dla rozwiązań SOTA.
ChatGPT to niezwykłe osiągnięcie, chociaż badania pokazują, że może być konsekwentnie wyprzedzany przez dedykowane modele SOTA. Nie możemy jednak nie doceniać jego wszechstronności. Ma niesamowitą zdolność dostarczania rozsądnych, gotowych rozwiązań dla wielu problemów językowych.
Pozwala nam to wyciągnąć pewne wnioski na temat tego, gdzie ChatGPT plasuje się w naszym świecie. Dzięki wygodnemu „konwersacyjnemu” interfejsowi użytkownika może stać się częścią naszego życia w postaci wirtualnego asystenta lub pomocy edukacyjnej. Ma również szeroki zakres zastosowań w dziedzinie wspomagania sztucznej inteligencji – pomagając inżynierom opracowywać lepsze modele ML. Może być używany jako zaawansowany mechanizm augmentacji tekstu lub wstępny adnotator danych – zapewniając srebrny standard dla innych modeli wstępnego szkolenia. Wiedza ogólna i zdolności poznawcze czatu pozwalają również na szybkie stworzenie bazowego modelu dla zadań związanych z wydobywaniem wiedzy (np. NER). Taki prototyp może być przydatny w wielu przypadkach, pamiętajmy jednak – dedykowane modele będą miały przewagę pod względem dokładności, szybkości i wydajności. W zastosowaniach komercyjnych, takich jak inteligentna automatyzacja czy przetwarzanie dokumentów, trudno przeoczyć te cechy.