Data annotation plays an integral part in every major Machine Learning project, at the same time being, by far, the most time-consuming and labor-intensive aspect of the process. Modern ML models are data-hungry, requiring a massive volume of labeled data to learn. As datasets are tagged manually, AI business hires a huge amount of workforce to generate that enormous volume of labeled data to feed their new models.
During this process it is paramount to maintain high quality of labels as it directly translates to the models performance. This becomes especially problematic when dealing with tasks requiring highly qualified professionals (e.g. labelling medical images or annotating legal documents). Even on top of that, there is a number of cumbersome challenges, such as maintaining the consistency of labeling, keeping human bias out of your data and much more. So... what can we do about it? Like true game-changers, lets think outside the box and try a completely different approach: Do we even need those labels?
Unsupervised Learning is a field of ML where the algorithms learn without any data labels or annotations. In cluster analysis, one of the main tasks of unsupervised machine learning, we let the model freely discover the dependencies in the data and group them into smaller subsets (called clusters) in such a way that points within a single cluster are more similar to each other than to representatives of other clusters. Maybe we could use this technique to perform ”unsupervised classification” and save us the trouble of annotating the dataset?
Let’s test this idea, where it could be the most useful; in the field where obtaining a big dataset with high-quality labels is notoriously difficult – Legal Machine Learning. Juridical documents, forms, contracts are often long and complicated, requiring highly trained professionals to carefully annotate them. This process usually takes hundreds of man-hours, draining the projects time and budget.
An example of such well prepared dataset is LEDGAR [3] – large-scale corpus of legal provisions in contracts. It contains 80,000 provisions manually labelled into 100 categories.
As a baseline we will train a supervised deep classifier – it produces an excelent score 95% accuracy. As an unsupervised model, we will use an experimental deep clustering ensemble method, developed by our engineers at 4Semantics – Snapshot Spectral Clustering (SSC) [2]. It combines the gain from generating multiple data views, while minimizing the computational costs of creating the ensemble – thus making the solution efficient when working with datasets as big as this one. The SSC model achieves an impressive score of 78% accuracy.
95% vs. 78% – supervised model surely outperformed the unsupervised one, but by how much? Let’s put this into perspective. When learning to perform this task, the supervised model had the manually distilled knowledge of highly trained lawyers at its disposal. The SSC model just needed to take a look at the documents – it’s all it took. When we take everything into account merely 17 percentage points gap does not seem as much.


Unfortunately – not yet. It’s a beautiful vision, but it is still way down the road. Cluster analysis could indeed replace supervised models without the need for costly labelling, but it is not as straightforward. As our example showed, there are real cases where clustering model is a viable alternative, but in general training unsupervised models is notoriously more difficult compared to their supervised counterparts. These models can be demanding when pushing for high performance for more than one reason. Beyond the fact, that the tasks they face is just harder, a number of different problems arise – e.g. as we do not explicitly ”tell” the model what kind of groups we are looking for, it can detect more than one pattern of grouping the data.
Still, despite the difficulties over the years unsupervised learning is clearly catching up. Along with the engineers and researchers pushing the scientific advancement forward, clustering models have another ally – sheer computational power. It has been shown that unsupervised learning benefits more from bigger models than its supervised counterparts [1] – this results in the technical advancement further unlocking the unsupervised potential.
Figure 1: Supervised vs. Unsupervised performance over the years on the STL- 10 benchmark dataset. [4]
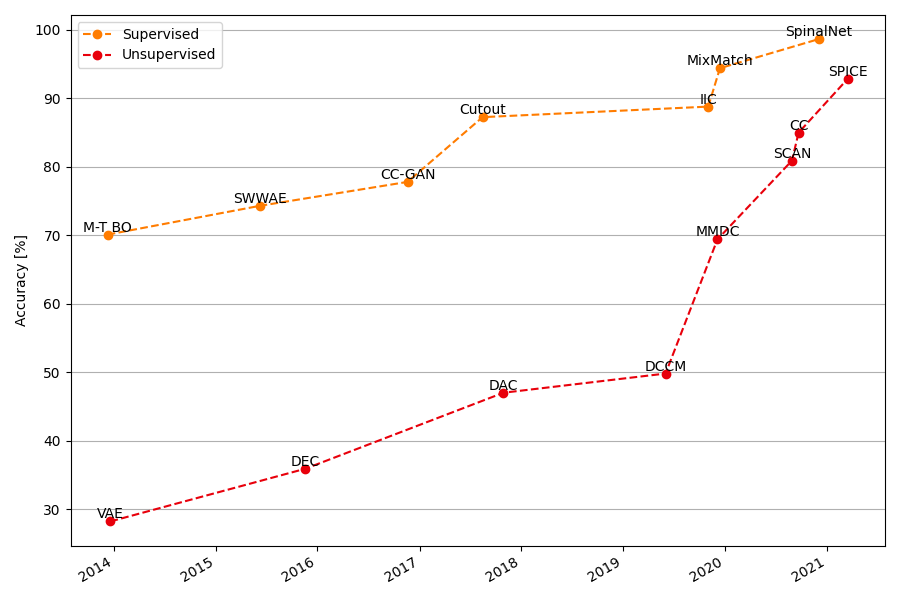
Due to the nature of the clustering tasks it is unlikely that it will straight up match the performance of supervised classifiers. Yet, one day it can become a viable alternative – raising the question if we want to achieve 80% performance right now, or 95% after investing substantial amount of time and money for labeling the data. This vision makes it worth for the engineers to keep refining known methods and looking beyond – for those yet unknown.
[1] Ting Chen, Simon Kornblith, Mohammad Norouzi, and Geoffrey E. Hinton. A simple framework for contrastive learning of visual representations. CoRR, abs/2002.05709, 2020.
[2] Adam Piróg and Halina Kwaśnicka. Snapshot spectral clustering – a costless approach to deep clustering ensembles generation. In 2023 International Joint Conference on Neural Networks (IJCNN), pages 1–8, 2023.
[3] Don Tuggener, Pius von Däniken, Thomas Peetz, and Mark Cieliebak. LEDGAR: A large-scale multi-label corpus for text classification of legal provisions in contracts. In Proceedings of the Twelfth Language Resources and Evaluation Conference, pages 1235–1241, Marseille, France, May 2020. European Language Resources Association.
[4] Papers with code: The latest in machine learning. https://paperswithcode.com/sota. Accessed: 2023-08-18.