Anotacja danych to integralna część każdego większego projektu uczenia maszynowego, będąc jednocześnie zdecydowanie najbardziej czasochłonnym i pracochłonnym aspektem tego procesu. Nowoczesne modele uczenia maszynowego wymagają ogromnej ilości oznaczonych danych, aby móc się uczyć. Ponieważ zbiory danych są etykietowane ręcznie, firmy wprowadzające rozwiązania z zakresu sztucznej inteligencji zatrudniają znaczącą liczbę pracowników do generowania tak dużej ilości oznaczonych etykietami danych na potrzeby nowych modeli.
Podczas tego procesu najważniejsze jest utrzymanie wysokiej jakości etykiet, ponieważ bezpośrednio przekłada się to na wydajność modeli. Wyzwanie jest szczególnie duże przypadku zadań wymagających zaangażowania wysoko wykwalifikowanych specjalistów (np. oznaczanie obrazów medycznych lub opisywanie dokumentów prawnych). Co więcej, istnieje wiele dodatkowych elementów, takich jak utrzymanie spójności etykiet, zapobieganie stronniczości danych i wiele innych, o których należy pamiętać. Co możemy z tym zrobić? Podobnie jak prawdziwi rewolucjoniści, wyjdźmy poza schematy i wypróbujmy zupełnie inne podejście: Czy etykiety w ogóle są potrzebne?
Uczenie nienadzorowane to dziedzina uczenia maszynowego, w której algorytmy uczą się bez żadnych etykiet danych ani anotacji. W klasteryzacji, jednym z głównych zadań nienadzorowanego uczenia maszynowego, pozwalamy modelowi na swobodne odkrywanie zależności w danych i grupowanie ich w mniejsze podzbiory (zwane klastrami) w taki sposób, aby punkty w obrębie pojedynczego klastra były do siebie bardziej podobne innych niż w reprezentacji innych klastrów. Może zastosowanie techniki „klasyfikacji nienadzorowanej” jest w stanie zaoszczędzić nam trudu związanego z opisywaniem zbiorów danych?
Przetestujmy ten pomysł tam, gdzie może być najbardziej przydatny; w dziedzinie, gdzie uzyskanie dużego zbioru danych z wysokiej jakości etykietami jest notorycznie trudne – uczenie maszynowe w branży prawniczej. Dokumenty prawne, formularze i umowy są często długie i skomplikowane, co wymaga starannego opisywania ich przez wysoko wykwalifikowanych specjalistów. Proces ten zajmuje zwykle setki roboczogodzin, wyczerpując czas i budżet projektu.
Przykładem tak dobrze przygotowanego zbioru tego typu jest LEDGAR [3] – wielkoformatowy zbiór zapisów prawnych w umowach. Zawiera 80 000 warunków, ręcznie oznaczonych w 100 kategoriach.
Jako punkt odniesienia wytrenujemy klasyfikator nadzorowany (supervised classifier) – daje on doskonały wynik osiągając 95% skuteczności. Jako model nienadzorowany wykorzystamy eksperymentalny model głębokiego klasteryzatora opracowany przez naszych inżynierów w 4Semantics – Snapshot Spectral Clustering (SSC) [2]. Łączy ona korzyści wynikające z generowania wielu widoków danych, minimalizując jednocześnie koszty obliczeniowe tworzenia zespołu, dzięki czemu rozwiązanie jest wydajne podczas pracy ze zbiorami danych tak dużymi jak ten. Model SSC osiąga imponujący wynik 78%.
95% vs. 78% – model nadzorowany z pewnością był lepszy od modelu bez nadzoru, ale o ile? Spójrzmy na to z innej perspektywy. Ucząc się wykonywania tego zadania, nadzorowany model miał do dyspozycji wiedzę wysoko wykwalifikowanych prawników. Model SSC musiał jedynie zapoznać się z dokumentami – to wszystko. Gdy weźmiemy pod uwagę to wszystko, zaledwie 17-procentowa różnica nie wydaje się aż tak duża.


Niestety jeszcze nie. To piękna wizja, ale wciąż wiele jest do zrobienia. Klasteryzacja mogłaby rzeczywiście zastąpić nadzorowane modele bez konieczności kosztownego etykietowania, ale nie jest to takie proste. Jak pokazał nasz przykład, istnieją rzeczywiste przypadki, w których model grupujący jest realną alternatywą, ale ogólnie rzecz biorąc, szkolenie modeli bez nadzoru jest znacznie trudniejsze w porównaniu z ich nadzorowanymi odpowiednikami. Modele te mogą być wymagające, gdy zależy nam na wysokiej wydajności z więcej niż jednego powodu. Oprócz tego, że stawiane przed nimi zadania są po prostu trudniejsze, pojawia się szereg różnych problemów – m.in. nie mówimy wprost modelowi, jakiego rodzaju grup szukamy, może on wykryć więcej niż jeden wzorzec grupowania danych.
Pomimo występujących trudności, uczenie nienadzorowane staje się coraz lepsze. Oprócz inżynierów i badaczy, którzy wpływają na postęp naukowy, modele grupowania mają jeszcze jednego sprzymierzeńca – czystą moc obliczeniową. Wykazano, że uczenie się bez nadzoru przynosi większe korzyści przy większych modelach niż jego nadzorowane odpowiedniki [1] – daje to nadzieję na wzrost wydajności uczenia nienadzorowanego w przyszłości.
Rysunek 1: Wydajność uczenia nadzorowanego i nienadzorowanego na przestrzeni lat, na zbiorze danych porównawczych STL-10. [4]
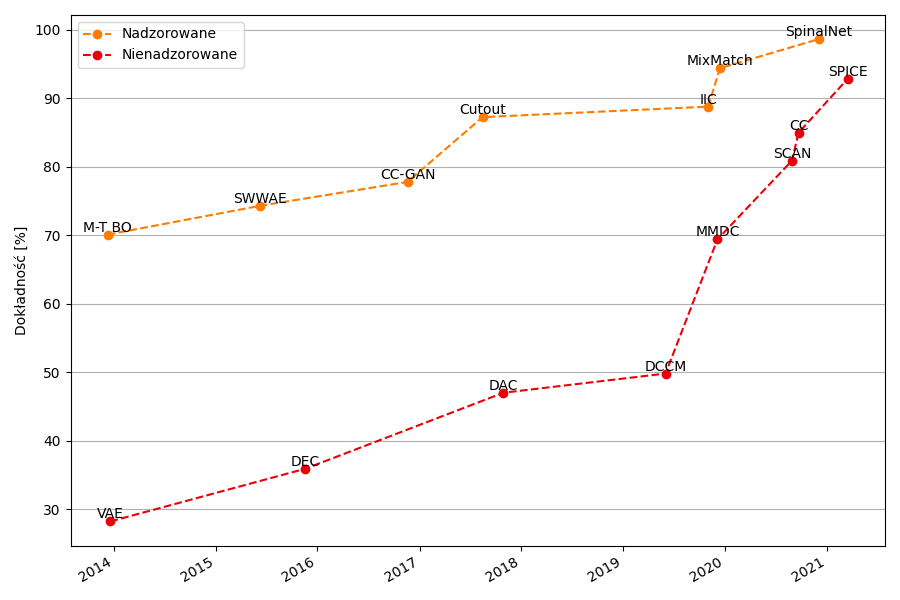
Ze względu na charakter zadań klasteryzacji jest mało prawdopodobne, aby modele nienazdorowane osiągnęły taką samą dokładność co klasyfikatory nazdorowane. Jednak pewnego dnia mogę one stać się realną alternatywą – wolimy osiągność 80% dokładności już teraz, czy 95% po zainwestowaniu znacznej ilości czasu i pieniędzy w etykietowanie danych. Ta wizja sprawia, że warto, aby inżynierowie kontynuowali udoskonalanie znanych metod i szukali dalej – odkrywając dotychczas nieznane.
[1] Ting Chen, Simon Kornblith, Mohammad Norouzi oraz Geoffrey E. Hinton. A simple framework for contrastive learning of visual representations. CoRR, abs/2002.05709, 2020.
[2] Adam Piróg and Halina Kwaśnicka. Snapshot spectral clustering – a costless approach to deep clustering ensembles generation. In 2023 International Joint Conference on Neural Networks (IJCNN), pages 1–8, 2023.
[3] Don Tuggener, Pius von Däniken, Thomas Peetz, and Mark Cieliebak. LEDGAR: A large-scale multi-label corpus for text classification of legal provisions in contracts. In Proceedings of the Twelfth Language Resources and Evaluation Conference, pages 1235–1241, Marseille, France, May 2020. European Language Resources Association.
[4] Papers with code: The latest in machine learning. https://paperswithcode.com/sota. Accessed: 2023-08-18.